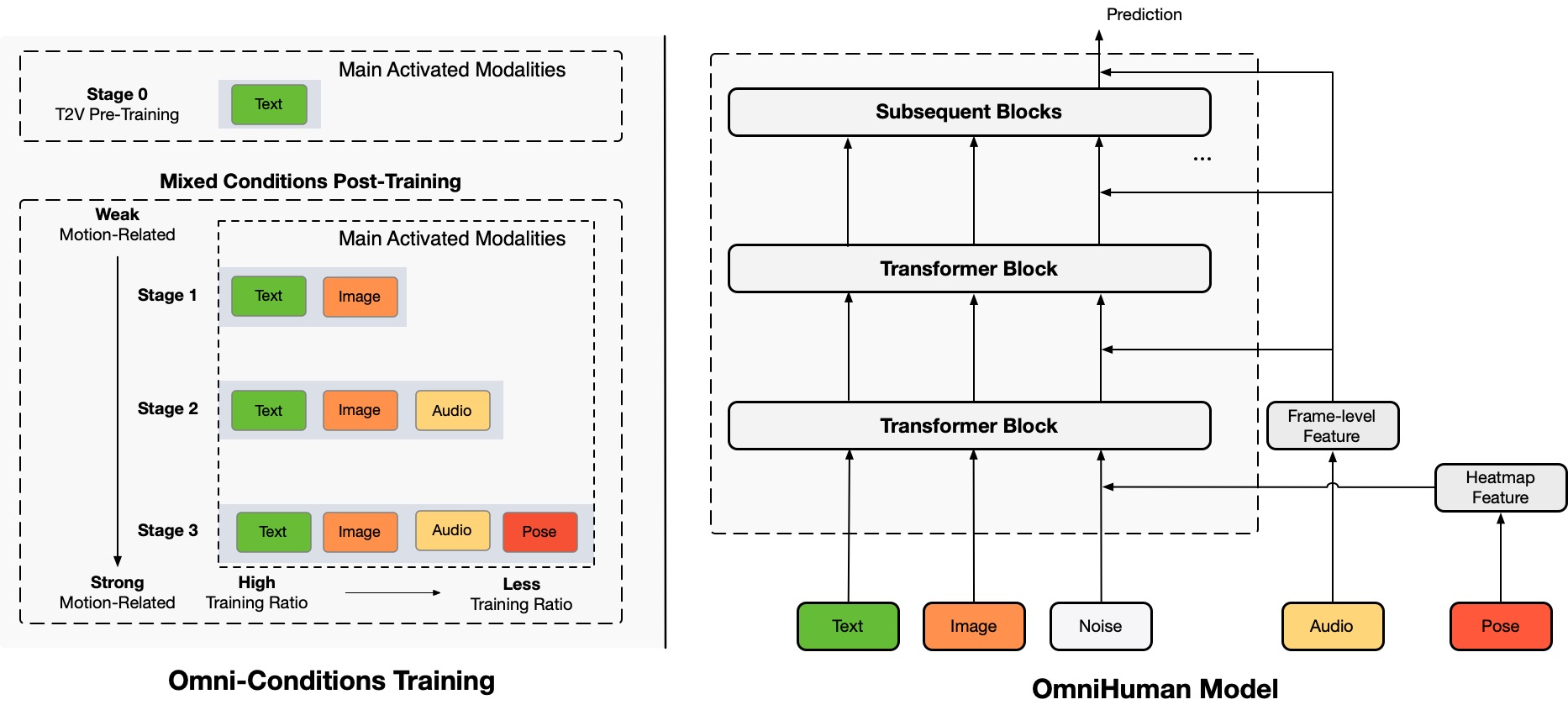
OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models
Gaojie Lin*, Jianwen Jiang*†, Jiaqi Yang*, Zerong Zheng*, Chao LiangByteDance Intelligent Creation *Equal contribution,†Project lead TL;DR: We propose an end-to-end multimodality-conditioned human video generation framework named OmniHuman, which can generate human videos based on a single human image and motion signals (e.g., audio only, video only, or a combination of audio and video). In OmniHuman, we introduce a multimodality motion conditioning mixed training strategy, allowing the model to benefit from data scaling up of mixed conditioning. This overcomes the issue that previous end-to-end approaches faced due to the scarcity of high-quality data. OmniHuman significantly outperforms existing methods, generating extremely realistic human videos based on weak signal inputs, especially audio. It supports image inputs of any aspect ratio, whether they are portraits, half-body, or full-body images, delivering more lifelike and high-quality results across various scenarios. Currently, we do not offer services/downloads anywhere, nor do we have any SNS accounts for the project. Please be cautious of fraudulent information. We will provide timely updates on future developments.
Generated Videos
OmniHuman supports various visual and audio styles. It can generate realistic human videos at any aspect ratio and body proportion (portrait, half-body, full-body all in one), with realism stemming from comprehensive aspects including motion, lighting, and texture details.
* Note that to generate all results on this page, only any single image and audio are required, except for the demo showcasing video and combined driving signals. For the sake of a clean layout, we have omitted the display of reference images, which are the first frame of the generated video in most cases. If you need comparisons or further information, please do not hesitate to contact us.
Diversity
In terms of input diversity, OmniHuman supports cartoons, artificial objects, animals, and challenging poses, ensuring motion characteristics match each style's unique features.
More Portrait Cases
Here, we also include a section dedicated to portrait aspect ratio results, which are derived from test samples in the CelebV-HQdatasets.
Singing
OmniHuman can support various music styles and accommodate multiple body poses and singing forms. It can handle high-pitched songs and display different motion styles for different types of music. Please remember to select the highest video quality. The generated video quality also highly depends on the quality of the reference image.
Compatibility with Video Driving
Due to OmniHuman's mixed condition training characteristics, it can support not only audio driving but also video driving to mimic specific video actions, as well as combined audio and video driving to control specific body parts like recent methods.
Ethics Concerns
The images and audios used in these demos are from public sources or generated by models, and are solely used to demonstrate the capabilities of this research work. If there are any concerns, please contact us (jianwen.alan@gmail.com) and we will delete it in time. The template of this webpage is based on the one from VASA-1, and some test audios are from VASA-1,Loopy,CyberHost.
BibTeX
If you find this project useful for your research, you can cite us and check out our other related works:
@article{lin2025omnihuman1,
title={OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models},
author={Gaojie Lin and Jianwen Jiang and Jiaqi Yang and Zerong Zheng and Chao Liang},
journal={arXiv preprint arXiv:2502.01061},
year={2025}
}
@article{jiang2024loopy,
title={Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency},
author={Jiang, Jianwen and Liang, Chao and Yang, Jiaqi and Lin, Gaojie and Zhong, Tianyun and Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.02634},
year={2024}
}
@article{lin2024cyberhost,
title={CyberHost: Taming Audio-driven Avatar Diffusion Model with Region Codebook Attention},
author={Lin, Gaojie and Jiang, Jianwen and Liang, Chao and Zhong, Tianyun and Yang, Jiaqi and Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.01876},
year={2024}
}